1 概念
数组(array)是一种线性数据结构,其将相同类型的元素存储在连续的内存空间中。我们将元素在数组中的位置称为该元素的索引(index)。图 1-1 展示了数组的主要概念和存储方式。
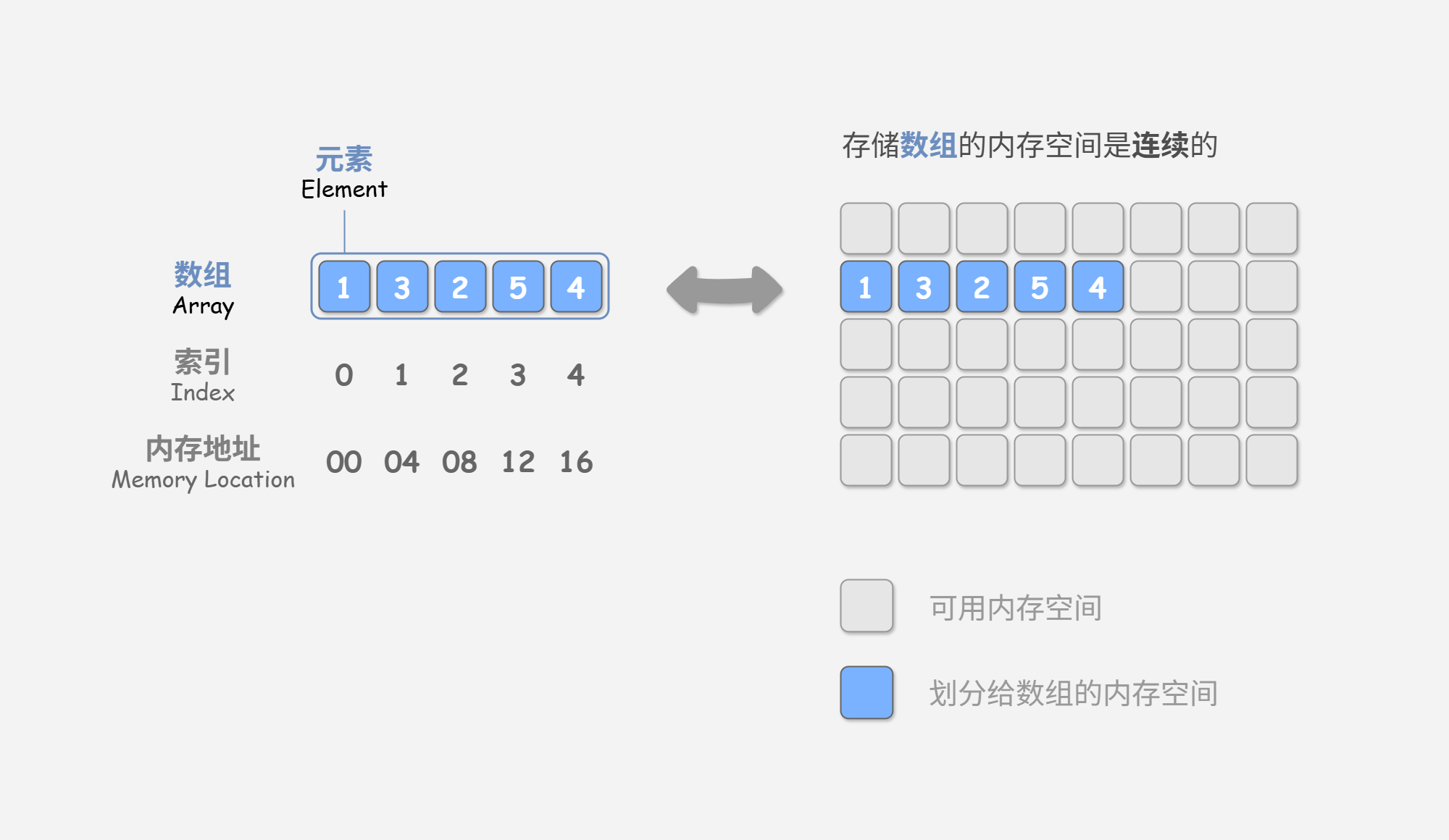
- 数组索引: 数组中的每个元素都有一个唯一的整数索引,从 开始计数。索引用于访问数组中的元素。
- 数组元素: 数组中的元素必须是相同类型的数据,可以是整数、浮点数、字符、对象等。
- 数组长度: 数组的长度是指数组中包含的元素数量。
- 连续存储: 数组中的元素在内存中是连续存储的,这这意味着可以通过索引直接访问元素。
2 数组常用操作
2.1 初始化数组
我们可以根据需求选用数组的两种初始化方式:无初始值、给定初始值。在未指定初始值的情况下,大多数编程语言会将数组元素初始化为 :
1 | /* 初始化数组 */ |
1 | # 初始化数组 |
2.2 访问元素
数组元素被存储在连续的内存空间中,这意味着计算数组元素的内存地址非常容易。给定数组内存地址(首元素内存地址)和某个元素的索引,我们可以使用 图 2-2 所示的公式计算得到该元素的内存地址,从而直接访问该元素。

观察 图 2-1 ,我们发现数组首个元素的索引为 ,这似乎有些反直觉,因为从 开始计数会更自然。但从地址计算公式的角度来看,索引本质上是内存地址的偏移量。首个元素的地址偏移量是 ,因此它的索引为 是合理的。
在数组中访问元素非常高效,我们可以在 时间内随机访问数组中的任意一个元素。
1 | /* 随机访问元素 */ |
1 | def random_access(nums: list[int]) -> int: |
2.2 插入元素
数组元素在内存中是“紧挨着的”,它们之间没有空间再存放任何数据。如 图 2-1 所示,如果想在数组中间插入一个元素,则需要将该元素之后的所有元素都向后移动一位,之后再把元素赋值给该索引。
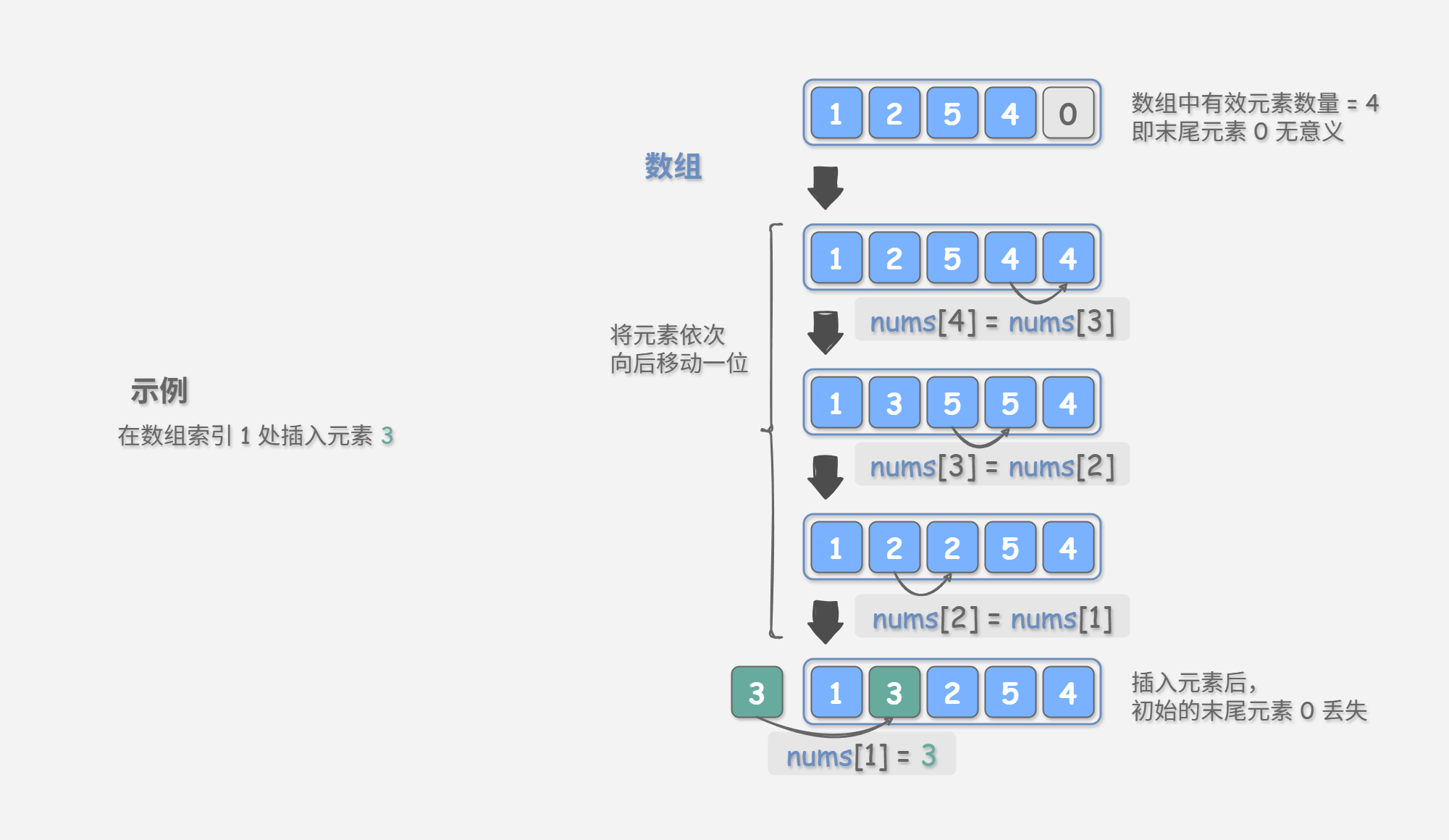
值得注意的是,由于数组的长度是固定的,因此插入一个元素必定会导致数组尾部元素“丢失”。我们将这个问题的解决方案留在“数据结构 —— 列表”章节中讨论。
1 | /* 在数组的索引 index 处插入元素 num */ |
1 | def insert(nums: list[int], num: int, index: int): |
2.3 删除元素
同理,如 图 4-4 所示,若想要删除索引 i 处的元素,则需要把索引 i 之后的元素都向前移动一位。
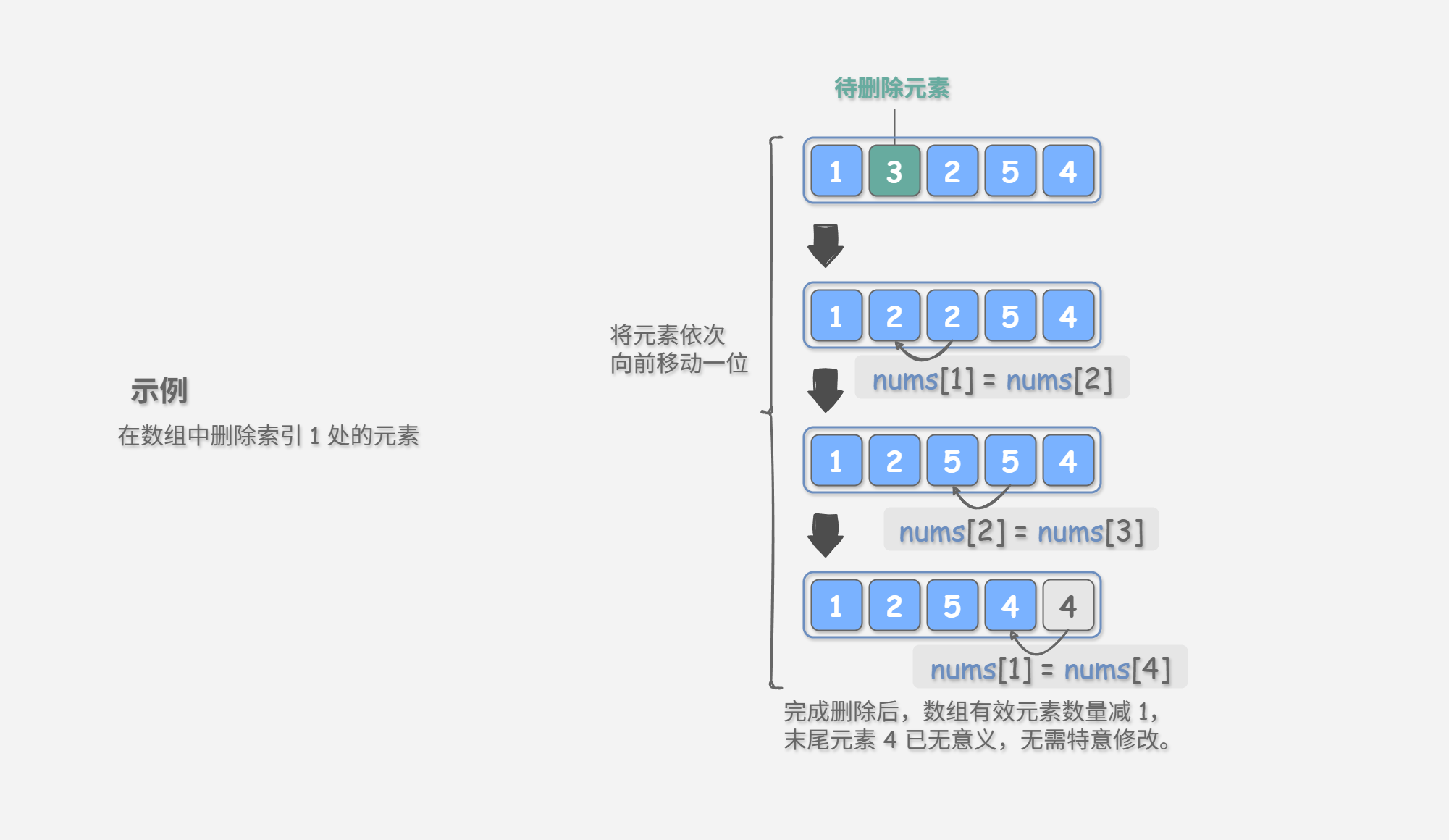
请注意,删除元素完成后,原先末尾的元素变得“无意义”了,所以我们无需特意去修改它。
1 | /* 删除索引 index 处的元素 */ |
1 | def remove(nums: list[int], index: int): |
总的来说,数组的插入与删除操作有以下缺点。
- 时间复杂度高: 数组的插入和删除的平均时间复杂度均为 O(n) ,其中 n 为数组长度。
- 丢失元素: 由于数组的长度不可变,因此在插入元素后,超出数组长度范围的元素会丢失。
- 内存浪费: 我们可以初始化一个比较长的数组,只用前面一部分,这样在插入数据时,丢失的末尾元素都是“无意义”的,但这样做会造成部分空间浪费。
2.4 遍历数组
在大多数编程语言中,我们既可以通过索引遍历数组,也可以直接遍历数组中的每个元素:
1 | /* 遍历数组 */ |
1 | def traverse(nums: list[int]): |
2.5 查找元素
在数组中查找指定元素需要遍历数组,每轮判断元素值是否匹配,若匹配则输出对应索引。
因为数组是线性数据结构,所以上述查找操作被成为“线性查找”。
1 | /* 在数组中查找指定元素 */ |
1 | def find(nums: list[int], target: int) -> int: |
2.6 扩容数组
在复杂的系统环境中,程序难以保证数组之后的内存空间是可用的,从而无法安全地扩展数组容量。因此在大多数编程语言中,数组的长度是不可变的。
如果我们希望扩容数组,则需要重新建立一个更大的数组,然后把原数组元素一次复制到新数组。这是一个 O(n) 的操作,在数组很大的情况下非常耗时。代码如下所示:
1 | /* 扩展数组长度 */ |
1 | def extend(nums: list[int], enlarge: int) -> list[int]: |
3 数组的优点与局限性
数组存储在连续的内存空间内,且元素类型相同。这种做法包含丰富的先验信息,系统可以利用这些信息来优化数据结构的操作效率。
- 空间效率高: 数组为了数据分配了连续的内存块,无须额外的结构开销。
- 支持随机访问: 数组允许在 O(1) 时间内访问任何元素。
- 缓存局部性: 当访问数组元素时,计算机不仅会加载它,还会缓存其周围的其他数据,从而借助高速缓存来提升后续操作的执行速度。
连续空间存储是一把双刃剑,其存在以下局限性。
- 插入与删除效率低: 当数组中元素较多时,插入与删除操作需要移动大量的元素。
- 长度不可变: 数组在初始化后长度就固定了,扩容数组需要将所有数据复制到新数组,开销很大。
- 控件浪费: 如果数组分配的大小超过实际所需,那么多余的空间就被浪费了。
4 数组典型引用
数组是一种基础且常见的数据结构,既频繁应用在各类算法之中,也可用于实现各种复杂数据结构。
- 随机访问: 如果我们想随机抽取一些样本,那么可以用数组存储,并生成一个随机序列,根据索引实现随机抽样。
- 排序和搜索: 数组是排序和搜索算法最常用的数据结构。快速排序、归并排序、二分查找等都主要在数组上进行。
- 查找表: 当需要快速查找一个元素或其对应关系时,可以使用数组作为查找表。假如我们想实现字符到 ASCII 码的映射,则可以将字符 ASCII 码值作为索引,对应的元素存放在数组中的对应位置。
- 机器学习: 神经网络中大量使用了向量、矩阵、张量之间的线性代数运算,这些数据都是以数组的形式构建的。数组是神经网络编程中最常使用的数据结构。
- 数据结构实现: 数组可以用于实现栈、队列、哈希表、堆、图等数据结构。例如,图的邻接矩阵表示实际上是一个二维数组。
5 数组的本质: 不仅是“连续内存”
5.1 数组真正的定义
数组的本质是: 一块连续的、等宽元素的内存区域 + 编译期已知的元素大小
1 | float temp[34]; |
1 | &temp[i] == (float *)((uint8_t *)temp + i * sizeof(float)) |
以上二者是等价的
这意味着三件非常重要的事情:
- 数组没有边界检查
- 数组访问是纯指针算术
- 数组“快”,是因为没有任何抽象层
5.2 数组 ≠ 指针
数组是“资源本身”,指针只是“引用”。
| 对比点 | 数组 | 指针 |
|---|---|---|
| 内存 | 连续、已分配 | 仅保存地址 |
| sizeof | sizeof(a)=40 | sizeof(p)=4/8 |
| 可赋值 | 不可 | 可 |
| 生命周期 | 跟随作用域 | 可动态管理 |
1 | int a[10]; |
5.3 数组作为接口参数: 你以为在传数组,其实在传指针
函数参数中的数组退化:
1 | void foo(int arr[10]) { |
输出是 4 或 8 ,而不是 40.
原因是:
1 | void foo(int *arr); |
在函数参数中,数组必然会退化为指针。
- 函数无法知道数组长度。
- 长度必须显示传递
1 | void process(float *buf, size_t len); |
这在:
- 协议解析
- DMA 数据处理
- 滤波算法
中是硬性设计规范。
5.4 静态数组 vs 动态数组( MCU 与 PC 的分水岭)
5.4.1 静态数组( MCU 首选)
1 | static uint16_t adc_buf[256]; |
优点:
- 内存确定
- 五碎片
- 实时性强
- 可放在 .bss / .data
缺点:
- 大小固定
- 占 RAM
在 MCU 里, 90% 的数组都应该是静态的。
5.4.2 动态数组(慎用)
1 | float *buf = malloc(n * sizeof(float)); |
问题不是“能不能用”,而是:
- 内存碎片
- 分配失败不可控
- 实时性不可预测
工程原则(嵌入式): malloc 只能出现在初始化阶段 (init) ,不能出现在控制环 / 中断 / 实时任务中
5.5 数组与 Cache :你看不到,但它决定了性能
Cache 友好性 (PC / Cortex-A)
1 | for (i = 0; i < N; i++) |
1 | sum += a[i * 16]; |
为什么第一种更快?
- CPU Cache Line (通常 32~64 Bytes)
- 连续数组访问 → Cache 命中率极高
这也是数组比链表快得多的根本原因之一。
即便在 MCU (如 M7 带 Cache) 中,这一点也开始变得重要。
5.6 数组的“形态进化”:一维、二维、本质一样
多维数组的真实面目
1 | float temp[3][4]; |
1 | float temp[12]; |
1 | temp[i][j] == *(temp_base + i * COL + j) |
- MCU 中避免过深多维数组
- 推荐“逻辑二维,物理一维”
1 | float temp[34]; |
5.7 数组的安全问题: 越界 = 潜伏炸弹
为什么数组越界在 MCU 中是“致命的”
1 | int buf[10] = {0}; |
在 PC 端:
- 可能“看起来能跑”
- 但其实已经 UB (未定义行为)
在 MCU 端:
- 覆盖其他变量
- 覆盖控制参数
- 覆盖返回地址
- 直接造成 HardFault
那么,为了避免:
- 所有数组都配长度宏
- 所有访问都经 index 校验
- 协议数据 → 先校验长度,再 memcpy
5.8 数组不是“被淘汰的结构”,而是一切的基础
在我如今的项目里:
| 场景 | 数组扮演的角色 |
|---|---|
| UART DMA | 环形缓冲区底层 |
| 温度采样 | 采样窗口 |
| PID | 历史误差缓存 |
| LUT | 非线性补偿 |
| 上位机 | numpy / list 的底层 |
环形缓冲区 = 数组 + 索引管理
队列 = 数组 + head / tail
数组不是“最简单的数据结构”,而是:
你是否理解内存、性能、边界、安全性的试金石。
作为成熟的工程师,切记:
- 什么时候改用数组
- 什么时候该换结构
- 数组大小是否可控
- 数组访问是否安全
- 数组布局是否高效